Самообучаващият се алгоритъм DeepMind на Google победи професионални геймъри на StarCraft 2, което бележи нова страница в развитието на AI
Играта е фундаментална за правилното развитие на децата, особено когато са малки. Чрез нея те се учат на различни елементи от живота, развиват отделни сегменти от мозъка и като цяло формират различни начини на логическо мислене. От конструкторите LEGO, през настолните игри, дори до компютърните – всички те могат да помогнат за формирането на определени умствени качества. Всяка една от тях изисква отделни етапи на обучение, при някои този процес е по-дълъг и изискващ, при други – всичко става доста по-бързо и лесно.
Например LEGO има различни конструктори за малки и по-пораснали деца. Така те могат да се обучат по-лесно на логиката на тези играчки, за да могат накрая да създават много по-сложни или изцяло собствени проекти.
Изкуственият интелект (AI) все повече може да го третираме като дете. Поради тази причина, голяма част от неговото развитие преминава през тестове свързани с различни игри. Също като при хората се спазва определена градация – някои са по-лесни за алгоритмите, други – по-трудни. Има съществена разлика – не е задължително игра, която човек бързо схваща, да е толкова елементарна за AI и обратното.
Поради възможността на изкуствения интелект да обработва много по-прецизно математически изчисления и да разглежда голям брой вероятности с малко неизвестни, той е силен именно в такива заглавия. Игри, които разчитат на различен тип логика, адаптивност в реално време и много неизвестни са голям препъни-камък за AI.
Алгоритмите толкова еволюираха, че вече самообучението им е нормална практика в развитието им. Което им помага да работят с много повече контекст, особено ако дадена игра разполага с много голямо количество информация от която те да изследват и наблюдават.
На 24 януари, звеното за самообучаващ се AI на Google – DeepMind – демонстрира в специален подкаст как тяхна версия разбива двама от най-известните професионални геймъри на StarCraft 2. Това постижение се счита за огромен пробив в изкуствения интелект и впечатли, както играчи, така и специалисти. То демонстрира възможността на специалния алгоритъм да се самообучи, гледайки основно повторения на професионални геймъри, да може да се развие сам чрез практика и накрая – да може да действа в ситуации в реално време, с огромен обем действия и с голям брой неизвестни фактори.
Ще се опитаме да обясним в следващите редове, защо всички тези неща са толкова трудни за AI и как се развива той в сферата на игрите.

Шах – детското забавление за AI
За да разберем повече за дългия път, който изкуствения интелект извървя, ще трябва да върнем лентата близо половин век назад. След създаването на първите компютри се правят опити да се създадат алгоритми, които да са майстори на легендарната игра шах. Тя е предпочитано средство, тъй като сравнително лесно могат да се зададат основните параметри и след това остават да се анализират различните ходове.
Предизвикателството – първите два хода съдържат сравнително малко възможни комбинации. След тях обаче възможностите скачат на над 400 при всяко местене на фигура на дъската. Към края на 60-те години на миналия век са създадени програми, които могат да победят сравнително неопитни играчи в турнирни условия (с времеви лимит между ходовете).
Развитието продължава, но все още няма програма, която да може да бие истински гросмайстор. Причината е, че според учените компютрите не разполагат с достатъчно изчислителна мощ да анализират и предвидят всеки един ход на шах. Съответно да могат да са максимално ефективни срещу най-добрите играчи на планетата.
От края на 80-те и началото на 90-те години се правят различни опити срещу опитни гросмайстори, но програмите не успяват да постигнат утвърдителни успехи. През 1997 г. IBM прекрачва тази невидима граница, като техния компютър Deep Blue успява да победи за първи път световния шампион по шах Гари Каспаров в турнирни условия. Последва близо десетилетие в което програмите и гросмайсторите си разменят победи.
Важно е да се отбележи, че голяма част от AI в този период разчита на предварително програмиране и ползването на суперкомпютри. С други думи, програмите имат база данни със ситуации, вкарани предварително, които с помощта на алгоритмите се анализират и се прави избор за най-адекватната. Различни вариации на тази технология се използва в системи, като Deep Blue, Fritz, Hydra и др.

Ролята на самообучението
През последните 20 години се развива друга система за разработване на изкуствен интелект. Тя включва машинно и задълбочено самоообучение (machine learning и deep learning). Целта е при нея AI да развие сам голяма част от възможностите в дадена сфера, с минимална човешка намеса. Примерно задават се базовите параметри, предоставя се достъп до достатъчно широка база данни и след това алгоритмите сами да могат да достигнат до правилното решение. Това важи с пълна сила при deep learning, при която AI е създаден така, че да се опита да имитира човешкия процес как да постъпи в дадена ситуация.
Технологията достига до истински бум през последните няколко години поради няколко фактора. Първият е в развитието на достатъчно добри дигитални невронни мрежи и системи за обработването на информацията. Вторият е в натрупването на огромни масиви от информация, от които алгоритмите могат да се самообучават.
Именно с помощта на тази технология DeepMind на Google успя през 2016 г. да победи световния шампион по древната китайска настолна игра Go. Последната е доста по-сложна от шаха, тъй като включва много повече комбинации – близо 130 хил. срещу само 400 при всеки ход. Създаването на единна база данни с всички възможности в Go е почти невъзможна. С което технологията използвана за разработването на AI за шах става неизползваема.
Това налага на учените да създадат процес на взимане на решенията, който да е близък до този на човека. Тук се намесват невронните мрежи и алгоритмите за самообучение. Победата на DeepMind и техния вариант AlphaGo има голямо значение – тя показва, че AI може да разпознае, използва и вземе решение в много сложни ситуации.
При Go, контекстът е много важен. Разположението на фигурите и разнообразието от ходове изискват много добра пространствена ориентация и логическо мислене. Нещо, което много трудно се постига само с предварително програмирани ситуации.
Година по-късно, AlphaZero – друг AI вариант на DeepMind – успява да се самообучи и да победи някои от най-добрите програми на шах. На изкуствения интелект на Google са му били необходими около 24 часа, за да постигне необходимите умения. След това побеждава или завършва наравно в 100 от 100 игри с най-добрата шахматна програма – Stockfish 8. Процесът по самообучение става при това без човешка намеса. Просто се пуска алгоритъмът да играе и сам да разпознае логиката и ходовете на шаха.

StarCraft 2 – скокът нагоре
Досега си говорехме за настолни и походови игри. В които двама играчи се редуват и имат поглед върху цялото табло и всички фигури. Може да звучи странно, но доста гейм заглавия са много по-сложни в своята същност, независимо, че хората по-лесно се научават на тях. Факторът забавление е много по-голям, контекстът и визията, която тез предлагат, се харесва много повече на геймърите. Шахът може да е изчистен, но в своята същност – доста скучно преживяване.
Достигаме до фундаменталния проблем, който братята (сега сестри – бел. ред.) Уашовски засягат в тяхната филмова трилогия „Матрицата“ – правото на избор. За хората е важно да имат възможността да определят своята съдба, независимо дали наистина това зависи от тях или е предварително зададено по определен начин.
Успешните компютърни игри обикновено разчитат именно на тази формула. Дават на играчите много повече възможности и право на избор.
StarCraft 2 е стратегия в реално време, която в професионалните среди на електронните спортове обикновено двама души строят бази, армии, изграждат виртуална икономика и се сблъскват един с друг, докато единия не се предаде или не бъде унищожен. За разлика от шаха и Go, тук имаме много повече елементи. Първо, целият геймплей е разделен на няколко части – изграждане на бази, след това управление на икономиката (събиране на ресурси и тяхното разпределение за какво отиват), строежът на армии и накрая – тяхното прецизно управление в битка.
Добавяме и редица неизвестни, които усложняват допълнително картината. Те са, че всичко става в реално време и самите играчи нямат изглед върху цялата карта, а само там където техните единици или сгради имат видимост. Получаваме един истински ад, в който алгоритмите наистина трябва да могат да действат като хора, за да са ефективни. Тук няма една универсална стратегия, всичко става за секунди, взимането на правилното решение и действие трябва да става за секунди. Независимо, дали е човек или изкуствен интелект – адаптацията спрямо ситуацията е задължителна.
Самата StarCraft 2 разполага с псевдо AI, който обаче „мами“ в целта си да бъде достоен противник. На първо място са премахнати неизвестните – компютрите имат знанието къде се намира играча по всяко време. Липсата на добро управление се компенсира с повече ресурси, които изкуствените противници получават, за да могат да се опрат на хората.
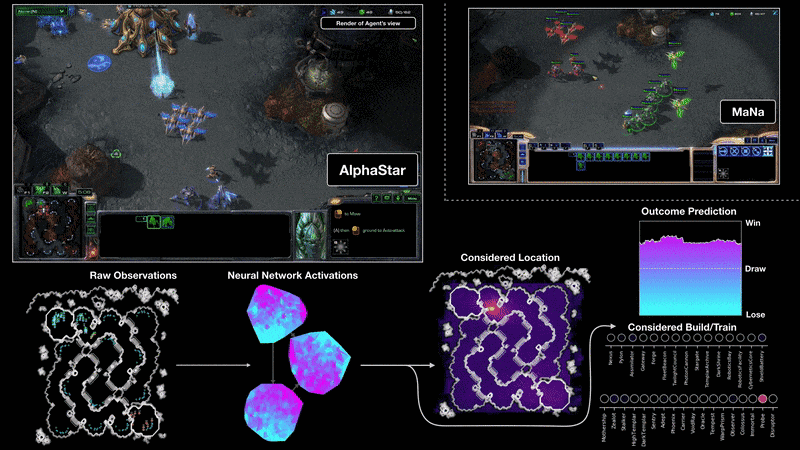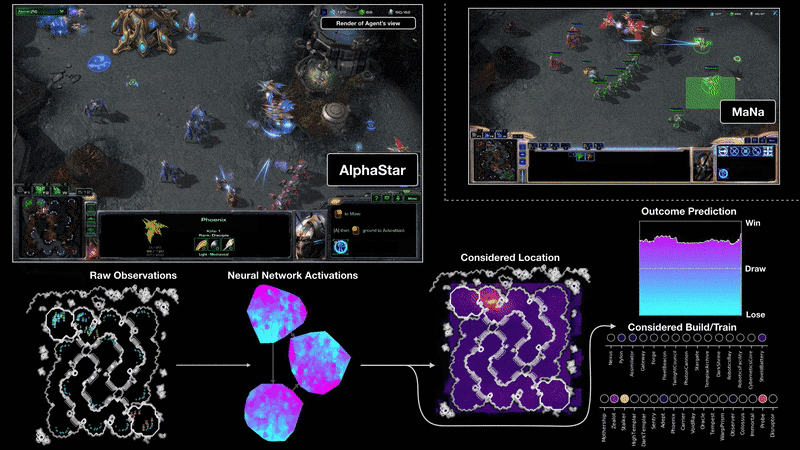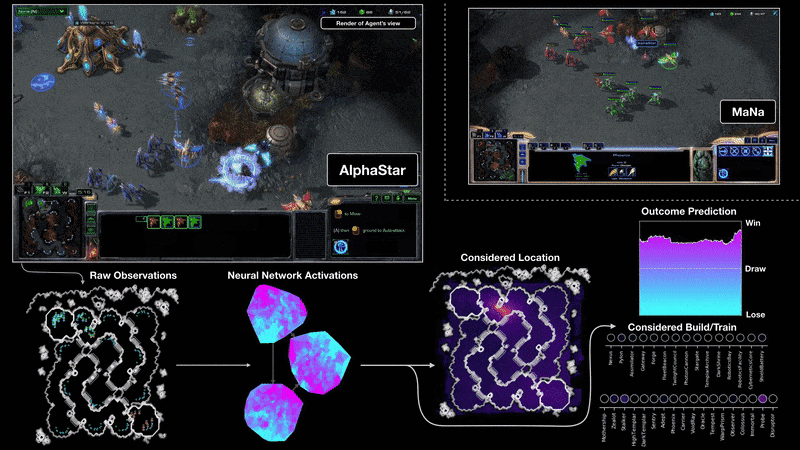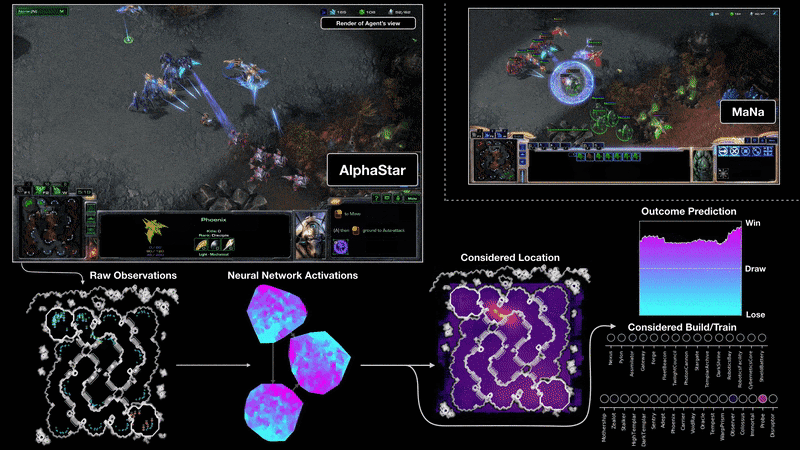
DeepMind на Google разработва нов алгоритъм – AlphaStar – чиято цел е да се научи да играе като професионален геймър на най-високо ниво. Използвани са последните технологии в рамките на невронни мрежи и задълбочено самообучение.
Резултатите не закъсняват. На 24 януари, този AI побеждава в директна битка двама от най-добрите и известни е-спортисти по StarCraft 2 – Дарио Вюнш, познат с псевдонима Liquid TLO (The Little One) и Гржегорз Коминч (Liquid MaNa). Първият пада с резултат 5:0, а втория – с 4:1. Видеото от цялата демонстрация можете да видите в края на материала.

AlphaStar – истинският е-спортист
За да постигне този резултат AlphaStar минава през истинска тренировка, като е-спортист. Изследователите от DeepMind създават алгоритъма и след това го „захранват“ с огромно количество записи от истински професионални двубои по StarCraft 2. След, като сам изучи основните на играта и базовите механики, на базата на наблюдение, AI се пуска в двубои срещу собствени копия. Като един мач приключи, се създава ново копие, което взима поуките от досегашните резултати, а предишните версии се самообучават. В един момент, DeepMind създават собствена лига, с различни версии на алгоритъма AlphaStar, които играят помежду си, по същия начин, по който функционира мултиплеър версията на играта с истински хора.
Изкуственият интелект има зададени няколко условности, които трябва да спазва. Той не може да извършва действие, което не му е в „погледа“. Подобно на играчите, които виждат само това, което са избрали на екрана, така и AI трябва да се съобразява с това правило. Не става ясно дали изкуствения интелект използва малката карта, която е безценен инструмент при задаването на множество команди.
По изчисления на DeepMind, след 14 дни функциониране на лигата, всяка версия е изиграла мачове с обща продължителност от около 200 години. На базата на резултатите са избрани две версии, които се пускат срещу истинските професионалисти.
Видеото, с двубоите на AlphaStar с TLO и MaNa, демонстрира, че изкуственият интелект наистина се държи като човек. Той разузнава, разширява си базите, пробва няколко стратегии и управлява почти перфектно своите армии.

Максимална ефективност
От мачовете с двамата професионални геймъри могат да се направят няколко извода. От една страна, AI взима някои нетрадиционни решения, които се смятат за противоречиви в професионалната StarCraft сцена. От една страна, AlphaStar не се колебае да атакува, т.нар. рампи – преходи между ниски и високи елементи на терена на картата. Е-спортистите ги избягват, защото много лесно могат да се заклещят единиците и съответно да направи по-бързо тяхното унищожение. Тази практика на няколко пъти изиграва лоша шега на AI, но тя не се оказва фатална. Дори напротив, в няколко от мачовете, смелото щурмуване на рампи, позволява на AlphaStar да победи решително своите човешки противници.
Друг момент, който прави впечатление е, че изкуственият интелект разчита на много по-малко разнообразие от единици. Той подбира или най-универсалните, или най-ефективните. Липсата на по-голяма комбинация се компенсира с невероятно управление на всяка една от тях. По този начин AlphaStar изстиска максимума на дадена единица по време на битка. Независимо, колко са добри професионалните геймъри, те просто няма да имат физическите сили да управляват перфектно и индивидуално над 100 единици при големите схватки. Нещо, с което AI се справя доста добре.
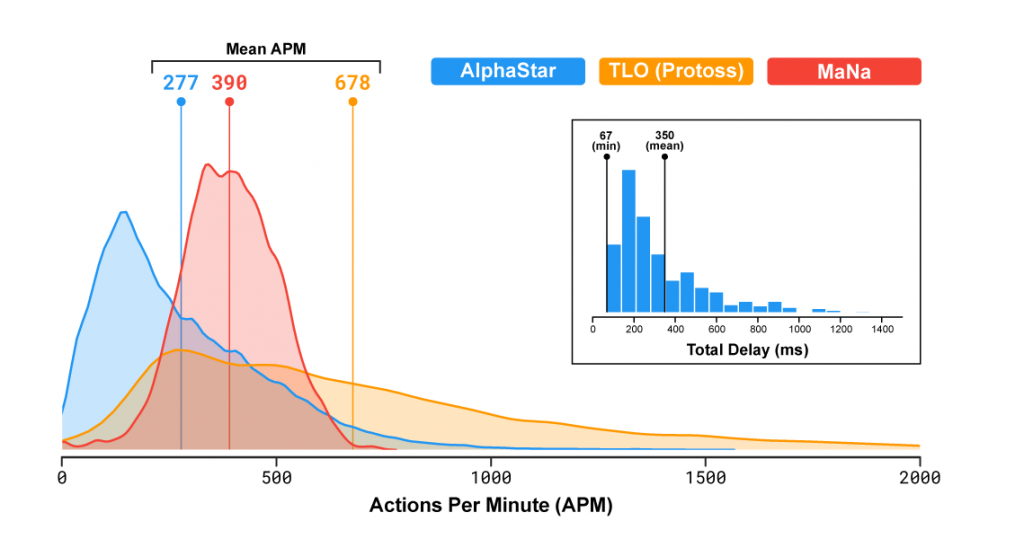
AlphaStar демонстрира и нещо друго – динамиката на един от най-важните показатели при професионалните геймъри на StarCraft 2. Това е т.нар. APM или действия в минута. Те показват, колко клика с мишката и натискания на бутони на клавиатурата прави даден играч в рамките на една минута. При е-спортистите този показател по време на игра не пада под 100 APM, като в напрегнати моменти може да надмине 500 или дори 600 (10 действия в секунда!). Средното варира между 200 и 350.
Изкуственият интелект показва средни стойности от около 250 APM, което е нормално за един професионален играч. Нещо, което беше и подчертано по време на демонстрацията. Това, което не беше показано е как се изменя динамиката на действията в различните фази.
Различни стриймъри, които получават достъп до повторенията в рамките на играта и съответно до пълните данни, разкриват малко по-различна картина. В моментите, когато няма битки или напрегнати моменти, APM-а на AlphaStar пада доста под 100, нещо, което е почти недопустимо за професионалните играчи. Причината е интересна – дори, когато няма какво да се върши, геймърите изкуствено поддържат висока активност, за да са подготвени за напрегнатите ситуации. Така те намаляват голямата разлика в APM в отделните фази на играта, поддържат по-добра концентрация на мозъка и мозъчна памет в ръцете. Това им помага по-бързо да превключат на високи обороти при големите битки.
AlphaStar е машина и много по-бързо превключва „оборотите“ на игра. Дори прекалено добре. Макар средния APM да е 250, в няколко игри е достигнат пиков момент от 1500 APM (или 25 действия в секунда!), което се смята за невъзможно за хората. Това доведе до предложения, да се ограничат максималните действия в минута на AI-а до 700-800. Благодарение на високия APM във възлови моменти и прецизното управление позволява на AlphaStar да премаже опонентите си само с един-единствен тип бойна единица – универсалният Stalker.
Някои условности
Постижението на DeepMind определено е огромен скок напред в създаването на самообучаващи се алгоритми, но има и доста още препятствия, които трябва да се преодолеят. Някои си проличаха и по време на самата демонстрация.
200 години игри, явно не са достатъчни да направят AlphaStar бързо адаптивен към напълно непознати ситуации. В последната схватка с MaNa, единствената в която изкуственият интелект губи, AI зацикля при опитите да отрази непрекъснати десанти в своята база от страна на човека. Тактиката позната, като „тормоз“ в професионалните среди има за цел с малко единици да се нанесе достатъчно поражения на места, където не присъства основната армия на противника. MaNa използва малка, но достатъчно силна армия, която може да удържи първоначалната контраатака от AlphaStar и след това да изчезне. В момента в който, основните сили на алгоритъма се завърнат на фронтовата линия, про геймърът повтаря операцията.
Въпреки, че в първите двубои, AlphaStar показва доста добри възможности за отразяването на малки десанти в база, по-големите го хванаха неподготвен. Което доведе до непрекъснато лутане на основната му войска напред-назад, без възможност да се адаптира към ситуацията. Човек лесно би спрял подобна тактика, но AI в случая се сблъсква с непозната такава и не намира рационално решение за справянето с проблема. Което показва, че AlphaStar има какво да учи още.
Допълнително, настоящата версия на изкуствения интелект може да се справя само с една от трите достъпни раси в играта (Terran, Protoss и Zerg). Причината е, че всяка една от тях е уникална с различни възможности, стратегии и елементи. Освен това AlphaStar може да се изправи ефективно и само срещу същата раса, с която играе (в случая – Protoss). Което беше проблем за LiquidTLO, тъй като германецът е добър със Zerg, макар, че преди десетина години се опитваше да се наложи в професионалните среди и с трите фракции.
Protoss, е и расата, в която цялостното управление и структура е една от най-лесните и бързи за схващане в играта. Последното ограничение е, че изкуственият интелект е подготвен да се бие само на една карта.
Всички тези лимитации все още намекват, че AlphaStar има още дълъг път да извърви, докато може да се справи в истинска турнира обстановка. Срещу различни раси, сменящи се карти и резки смени на тактиката на противниците. Но скокът от Go към StarCraft 2 е повече от впечатляващ и няма да се учудим, ако скоро коронясаме първия изкуствен интелект, който е победил на турнир най-добрите геймъри на света.
Пълният запис на демонстрацията на DeepMind: